搜索技术,无论是对个人,还是对企业,都是非常重要的技术。
 (资料图片)
(资料图片)
互联网信息技术,对于人类来说,最本质的改变在于,极大地扩大了人类的信息获取半径。
2017 年,IDC 发布的《数据时代 2025》白皮书中,就提到了互联网中的信息总量,到 2025 年,将大财 160 亿ZB,按照全球的网民按照 50 亿人计算,意味着每个人将被分配到 3.2 ZB 的信息量。这样的信息量,是在互联网之前的时代,在靠书本和语言传播信息的年代无法想象的。
面对海量的信息,如何找到我们所要的信息,是在互联网时代必备的技能之一。而搜索技术,就是这样一把利器,让用户更快地找到自己想要的内容。
回顾互联网的发展历程,起初新浪,网易等各大门户网站是用户浏览的主要站点。但很快,随着互联网信息的增长,门户分类的方式已经无法满足用户寻找信息的需求。接下来的故事,大家也就知道了,像 Google、百度这样的公司,依靠搜索引擎技术,找到了新的商业变现模式——“关键词广告”,成为了 PC 互联网时代的王者。
我们每天都在使用着各种各样的搜索功能,在微信里,在小红书里,在手机系统里,在浏览器里,我们都在“搜索”。
那么搜索到底是一个怎样的技术呢?
他是怎样做到让我们如此之快地找到想要的信息的呢?
一、搜索
搜索功能,本质上都是在数据库里进行检索。
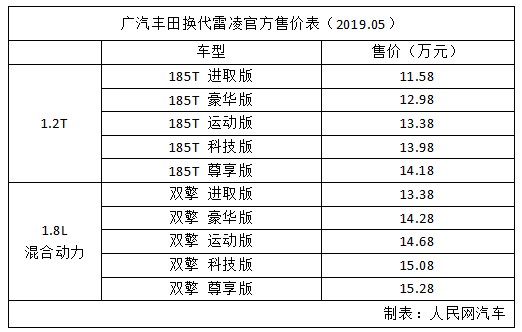
比如,在一个人才数据库中,高启强的数据是:
可以理解为,在一份纸质表格里找数据。例如现在在一个 20 行 6 列的表格里,我们有找到高启强的信息,那么只要从第 1 行到第 20 行,每行 5 个数据局都过一遍,直到高启强。这就是搜索。
这样的搜索方式在数据库量级不大的情况下是可行的,但如果数据量上升,达到 2000 万行,那原来的方式,就行不通了。所以就需要使用更高效的搜索,也就是通过建造[[索引]]的方式来提高搜索速度,例如,京海市的人才库里有 2000 万人,如果我先找到姓“高”的人才,再从高姓人才中查找高启强,速度则会快很多。
在 Elasticsearch 中,使用到的“倒排索引”技术来提高搜索的有效性和可用性。
例如 ES 会为高启强建立这样的索引:
38 岁 ~ 高启强 鱼贩 ~ 高启强 京海市 ~ 高启强
这样,我在搜索京海市的鱼贩时,也可以搜索到高启强,提高了搜索的有效性和准确性。
(倒排索引示意图,图片来源于网络)
二、全网搜索 vs 站内搜索
上面讲到,搜索本质上都是在自己的数据库中检索,那么根据一般根据搜索的范围划分,我们可以将搜索技术分为全网搜索和站内搜索
全网搜索,如 google,百度站内搜索,如 淘宝、微信里的搜索
两者的区别在于,全网搜索需要检索全网的内容,所以搜索引擎需要利用爬虫技术,爬取网页的资料,整合到自己的数据库中,才能被用户搜到。例如 google 的 spider 爬虫机器人,就会定期爬取全网的所有页面,收录到 google 的系统中。只有被收录的网页,才能够在 google 搜索到。
而站内搜索,因为搜索的内容都是自己的,所以更重要的是怎样将内容更好地组织好,放到搜索引擎中,让用户更快搜索到。举一个大家日常都在使用的例子 —— 微信搜索:微信就将自己的搜索结果分为聊天记录、联系人、文章、表情、百科……等等不同的分类,让用户更快地找到想搜的内容。
三、点击搜索后,发生了什么?
由于个人的工作经历相关,之前在一个电商平台中负责搜索相关的需求。所以今天我们主要来聊聊站内搜索功能。
一切搜索的行为,是从用户输入一个搜索词开始的。当我们在搜索框中输入一个词,点击搜索后,发生了什么?
我画了一张搜索功能的图景:从一个关键词开始,搜索服务会怎么处理,最终返回搜索结果,如下:
接下来就分为一个部分来简单讲讲搜索服务的流程。
1. 文本分析器
当收到一个“搜索词”后,并不能马上发起搜索,而是要经过文本分析和处理,再使用处理过后的文本发起搜索。
1)分词
用户在输入框中,输入的可能是一个句子,可能是一个短语,可能是一个词。用户的意图是多样的。这就是需要我们对用户输入的词语进行分词和理解。
例如用户输入的搜索词是“珠江新城咖啡厅”,这样的词语,经过分词算法的处理,可能会识别出以下几个搜索词“珠江”,“珠江新城”,“咖啡”和“咖啡厅”。
分词算法,使用自然语义识别 (NLP)和词频分析等技术,比较复杂。对小公司而言,可以使用一些开源的分词技术。大公司可能会根据自己的业务对分词算法进行优化,例如美团技术团队的文章中《美团搜索中 NER 技术的探索欲实践》就提到了:在进行实体字典匹配前引入了CRF分词模型,针对垂直领域美团搜索制定分词准则,人工标注训练语料并训练CRF分词模型。
在我们之前做的海外项目的分词中,因为目前没有开源的针对小语种的分词器的,于是只能使用最基础的空格分词。例如用户输入的是“Beşiktaş Coco Bean Coffee”,经过分词后,会得到“Beşiktaş”,“Coco”,“Bean”,“Coffee” 几个词,加上原文本一起分别进行搜索。
2)特殊词处理
分词结束后:
部分被禁止的词语,政治相关或色情相关的搜索词,会被移除,不然,可能就会请喝茶了。 有些预期主持,例如“吗”“啊”等停用词,会被移除。例如用户搜索的词语是“附近有咖啡厅吗?”,其实就可以理解为“附近”和“咖啡厅”,“有”和”吗“是可以去掉的。
3)同义词识别
有些含义相同的词语,例如经典的“西红柿”和“番茄”,这些同义词,需要人工维护,搜索运营会观察搜索数据,讲一些常见的同义词,维护关联到一起。这样搜“西红柿”的时候,也可以搜到“番茄”的结果。
4)实体识别(类目预测)
实体识别是根据用户输入的搜索词,预测用户想要搜索的实体(如商品、内容、表情等)。这一技术非常重要,可以很大提高搜索的准确度。
例如“珠江新城咖啡厅”这个搜索词,在被分词为“珠江”,“珠江新城”,“咖啡”和“咖啡厅”后,其中一些词语会命中特点的类目,例如“珠江新城”会命中商圈、地铁站的实体词库,“咖啡”会命中食物分类的实体词库,“咖啡厅”会命中餐厅类型的实体词库。
这样的实体识别,可以预测用户的搜索意图,在下方做搜索结果的排序时,提高对应实体的排序。比如,在微信搜索中,如果你搜索“高启强表情”,那么微信会优先展示表情的搜索结果。
2. 搜索
搜索的过程,实际上可以分为召回和排序两步:
召回:把符合的搜索结果拿回来 排序:按照排序规则,对召回的结果进行排序
1)召回
召回时常见的问题是在「召回率」和「精确率」的取舍。
召回数据的太多,可能会导致召回了不相关的结果。召回的数据太少,有可能导致想要搜索的结果没有召回。
我们可以通过增加筛选条件,通过实际识别技术,对不同的实体提供不同的召回率来优化搜索结果。
例如还是在高启强的案例中,通过名称来搜索“高启强”的的人数肯定是最多的,也就是“姓名”这个实体重要性最高。通过搜索“旧厂街”来搜索的人数其次,“住址”这个实体可以列为中等重要。而通过身高来搜索高启强的人数肯定比较少,重要性最差。当用户搜索 175 时,就没必要召回高启强的数据。
2)排序
常见的排序,是按照单一维度的排序。例如从近到远排序,评分从高到底排序。
早期的大众点评,提供了这样的排序方式,但是因为单一维度的排序,往往很难满足用户的需求,会导致搜索结果中出现大量低质量的门店。所以后来,大众点评也将“从近到远”优化成了“距离优先”,将“评分从高到低”优化为“好评优先”,在距离和评分的基础上,加上了其他考量因素。这样既优化了用户体验,也提高了商业效率。
复杂的排序方式,比如按照“相关度打分”算法排序,是根据文本的匹配度,对不同的搜索结果进行打分。让相关度更高的搜索结果,分数就越高。例如在 Elastic search 的全文搜索中,默认根据 BM25 算法来计算文本相关度,根据文本匹配度来排序。
基于相关度算法,不同的实体之间的相关度对打分的影响,也是可以调节的。
在之前的海外 O2O2 交易平台中,当分词命中了实体词库后,我们会适当提高提高实体打分的权重。
例如我在大众点评中,搜索“珠江新城”这个词时,如果只考虑店铺的名称,那么名称里含有“珠江新城”的搜索结果会排在前面,比如“XXX(珠江新城店)”,但这并不是用户希望看到的,所以此时应该提高“商圈”的实体在打分排序中的权重。相应地,在搜索结果中,会优先展示珠江新城商圈、咖啡厅的餐厅类型,咖啡的食物分类的搜索结果。至于提高多少,就需要根据实际情况来调优了。
3. 结果展示
通过搜索,拿到数据后,最后一步就是搜索结果的展示了。也就是大家搜索后看到的页面。各个应用可以根据自己的业务特点,设计对应的展示样式。
在设计时需要考虑的是:
1)数据的展现样式
例如在淘宝搜索不同商品时,展示的方式不一样的,有的双列瀑布流,有的是通栏的列表。
例如在微信中,搜索不同的内容,文章、视频号、表情、百科等的展现形式都是不同的。
2)展示每一个搜索结果的哪些信息
例如在大众点评中,每一个搜索结果都包含标题、图片、评价、地理位置、距离、商圈、用户评价、是否有套餐等等信息。产品设计是应该思考的是如何设计一个卡片的展示,在提供用户想要的消费决策信息的同时,保证页面的简洁美观,提高搜索的有效性。
4. 其他搜索相关的产品设计
还有一些其他的搜索产品设计,这里也简单讲一讲。
1)搜索联想词
例如在淘宝的搜索框输入词语时,他会自动联想你想搜索的结果。
搜索联想词的实现方式,是将平台中常见的搜索词作为一个库,当输入文本时,就通过前缀匹配来获取数据,再根据搜索频次等其他数据排序,展示成列表。
2)热搜词
热搜词、或这是热搜榜单,出现在搜索页。
主要目标群体是给不知道要搜索什么的用户提供一些热门的搜索项。
3)特殊的结果样式
例如在淘宝中搜索店铺名的时候,店铺会以一个特殊的卡片样式出现在顶部。
在信息流中,还可以插入广告,插入其他内容等等。例如,在淘宝搜索商品时,商品流中会穿插着广告、搜索建议、用户调研、榜单、内容推荐等等。
4)排序方式和筛选
排序方式和筛选通常是放在一起将的,但在【搜索】部分已经提及,不再赘述。
而筛选方式,是提供用户主动选择的,帮助自己快速定位信息的工具。根据不同的也谁,筛选项会有很多。
举个例子:
贝壳找房搜索的筛选器:可以根据行政区域,地铁站、地标、整租/合租、租金范围,活动,楼层,设施等等来进行筛选; 淘宝搜索的筛选器:可以根据折扣类型,价格区间,发货地,店铺所在城市等等进行筛选。
筛选器的设计也都大同小异,许多交互已经标准化了。
四、结语
总结一下,这篇文章主要介绍了站内搜索的基本原理、相关设计和优化方法。当用户输入一个关键词后,要经过文本分析后,进入搜索服务。搜索服务处理后,返回的搜索结果,前端再根据合适的展现方案展示,这是搜索的基本流程。除此之外,还介绍了一些搜索相关的产品设计、热搜词联想词等等。
这篇文章可以算是搜索产品的基础,了解这些可以帮助更好地理解搜索技术。
文章不足之处,主要在于对于人工干预搜索的部分,没有很好的展现。大多数产品都会做自己的搜索后台,用于让搜索运营处理无结果搜索结果优化,同义词识别,敏感词维护等等。这些内容,后续有机会再分享。
对于互联网产品,无论在电商平台还是内容平台,搜索都是用户高频使用的,寻找信息的方式。在日常生活中,搜索也是我们高频使用的。
本文由 @潦草学者 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
关键词: 站内搜索 如何让我们找到想要的信息 搜索引擎